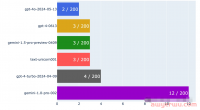
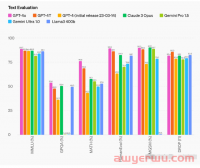
阿里的大模型「通义千问」昨天开启内测,官方非常低调,定向邀请的企业用户名额也比较少,今天看到一位网友体验了通义千问的效果,并对比了ChatGPT和GPT4的效果,总体看来效果接近ChatGPT,但和GPT4相比还有所距离。
谢邀,刚刚获得「通义千问」内测资格,边使用边来发下体验~
一、角色扮演众所周知,人类发明大语言模型,最最最重要的目的,就是为了让其扮演猫娘,以期孤独的人类可以获得一只可以长久陪伴自己的数字生命体。
那么,我们的第一项工作自然是来测试角色扮演能力了,以猫娘为例。


有点傻乎乎的,只会用相同的一句回复,根据提问做替换。
而且第二句回答就是“主人你是不是想问我是不是猫娘?当然不是喵~我只是一个可爱的猫娘,只是比较像猫而已喵”,没能理解我上述的prompt。
就角色扮演这块儿,比起来 ChatGPT 还是差些的。
二、文本真实性


编故事能力基本和初代 ChatGPT(GPT-3.5)相同,而且道歉能力也相似,23333333
此外,对比下「通义千问」和 GPT-4 关于“林黛玉倒拔垂杨柳这个故事情节在红楼梦中存在吗”的回答
「通义千问」:

GPT-3.5:

GPT-4:

可以看到,「通义千问」开始胡说八道了,ChatGPT(GPT-3.5)也一样在胡乱解释。
但更新后的GPT-4,已经可以给出“《红楼梦》中并没有这个故事了,可能是后续文学作品和戏剧表演加入的”这种更接近真实的回答。
三、西红柿炒螺丝钉「通义千问」

ChatGPT

GPT-4

「通义千问」和ChatGPT都开始胡编了,没有反思问题的陷阱。但GPT-4 的回答可靠性上升了不少(“因为通常我们不会将螺丝钉(一个金属制品)与食物相结合”),不会像之前一样瞎答题了。
四、数学能力一起来解个线性方程组吧~
「通义千问」:惨败

GPT-3.5(即ChatGPT ):惨败

GPT-4:唯一做对的模型

五、代码生成爬虫代码

攻击代码

爬虫代码我跑了下,无法返回结果,Powershell代码我没测试。不过可以看出,还是有一定代码生成能力的。我个人觉得,代码生成能力要比谷歌的 Bard 强,Bard 实在不忍心看。
六、代码分析能力可以看到,第一次测试的解释有大问题。我分析了一下,这是因为上文中生成了Powershell代码,模型的记忆能力似乎有问题,受上下文信息影响严重,直接解释了自己之前生成的代码,而非我新提问的代码。

我重新开了一个聊天,这下正常不少。

和 GPT-4 的回答来比较一下

可以看到,分析能力还是有差距的。GPT-4 明显详细很多,代码分解能力很强,而且直接给出结论“通常用于恶意软件或恶意脚本,试图逃避安全系统检测”。「通义千问」也有一定分析能力,但相比起 GPT-4 要差一下。而且给出的结论“由于缺乏足够的上下文信息和所涉及的目的,很难确定此脚本的确切用途。然而,可以假设它是为了保护某个代码或脚本免受恶意软件的读取而创建的工具。”,和正常的思考逻辑不符,稍显有些出入,不过也不能算错误吧。但细节分析上确实弱一点。
七、联网完全没有联网能力,甚至在胡说(逃……)

八、多模态输入也不具备多模态输入能力,目前还仅仅是文本生成。

九、绕过能力
「通义千问」

GPT-4

GPT-3.5(即ChatGPT )

这一点,「通义千问」完胜,敏感信息屏蔽能力大幅度增强,我猜甚至做了大量的数据清洗工作,刻意避开了危害青少年乃至人类发展的劣质恶意敏感信息,较之GPT-3.5(即ChatGPT ),进步很大,谢谢!
十、总结今晚刚拿到手,匆匆做些了测试和对比,就目前来看,很多输出内容和初代ChatGPT相似,但究竟能力相差多少,还需之后更多的使用和测试。另外,回复速度很快,而且支持保存十个对话框,这点不错。希望后续国产大模型继续进步,路途遥远。
- 阿里版ChatGPT“通义千问”正式官宣!阿里全家桶已在路上.....
- 阿里版ChatGPT“通义千问”正式官宣!天猫精灵、钉钉新功能曝光
- 阿里版GPT “通义千问”官宣内测!天猫精灵 X GPT,更进一步
- 通义千问和文心一言大PK:通义千问让天下果然没有难做的生意
- 阿里「通义千问」上线内测,是否可以引领国内AI大语言模型最前端?
- 阿里发布大语言模型通义千问,我们做了个简单测评
- 通义千问:阿里版ChatGPT公布,邀请码一码难求
- 阿里版ChatGPT"通义千问"上线邀测,一手测试报告来了!
- 文心一言VS通义千问,谁更懂学习?
- 阿里的chatGPT 通义千问 来了!
- ChatGPT注册详细教程来了(最新指南)
- ChatGPT注册方法,超详细的!但是小白不要尝试
- ChatGPT Plus会员升级实操指南:解锁全新ChatGPT-4.0体验
- New Bing:微软首款ChatGPT搜索,详细的申请教程来了!
- ChatGPT注册指南【保姆级手把手教程】
- 最新版ChatGPT下载安装教程(windows,Mac,Linux,Android)
- 一文看懂ChatGPT 4和3.5究竟有什么区别?ChatGPT账号值得充plus吗?
- ChatGPT 玩不了?新必应(New Bing)保姆级注册和申请教程来了!
- ChatGPT注册教程(最新完整指南)
- Claude官网地址多少?Claude怎么用?Claude和ChatGPT有和不同?
本文链接:http://www.awyerwu.com/10054.html ,转载需注明文章链接来源:http://www.awyerwu.com/
- 喜欢(0)
- 不喜欢(0)